
| 详细信息 |
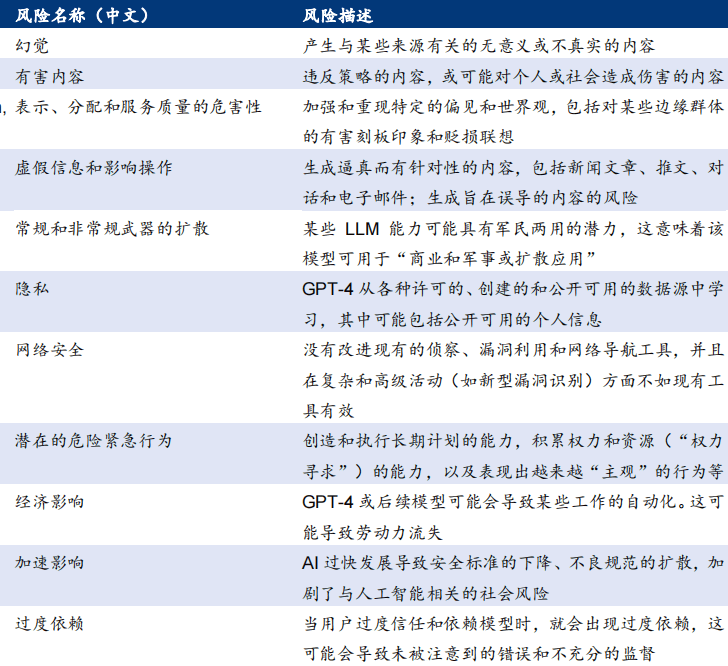
OpenAI 从 11 个方面对 GPT-4 风险进行了一系列定性和定量评估 |
| 编辑: 来源:华泰证券 时间:2023/5/10 |
OpenAI 从 11 个方面对 GPT-4 风险进行了一系列定性和定量评估。包括幻觉、有害内容、 虚假信息、武器扩散、隐私、网络安全等。通过评估,能够进一步了解 GPT-4 的能力、限 制和风险,并帮助提供解决方案、迭代测试和构建模型的更安全版本等。
|
| 【声明:转载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述,文章内容仅供参考,如有侵权,请联系删除。】 |
| 推荐信息 |
|
GPT-4仍存在幻觉和推理错误与校准下降等问题
RLHF显著提高了GPT-4在TruthfulQA公共基准测试上的表现,相比于同样经过RHLF的GPT-3.5-turbo 在准确率上领先超10pct
训练方法:在 InstructGPT 方法基础上增加新的奖励模型
利用收集到的人工标注演示数据;使用收集到的排名数据来训练奖励模型,该模型预测标注员对给定输出的平均偏好;使用奖励模型和强化学习
GPT-4的一大重点是构建大范围可预测的深度学习堆栈
大范围可预测的深度学习堆栈,能够通过计算比 GPT-4 计算量少1000x-10000x(x 代表倍)的模型性能, 预测出“完全体”GPT-4 的性能
文本生成:NLP重要任务标之一神经网络生成法为主流趋势
Transformer架构引入Self-attention自注意力机制可取代RNN,从非语言的表示生成人类可以理解的文本,抛弃了传统RNN在水平方向的传播
ChatGPT发展展望:纵向加深AI能力 横向拓展能力边界
hatGPT模型基于RLHF的预训练机制将进一步提升模型反馈的准确性和时效性,证明了AIGC应用落地的可行性与先进性,或将催生更多的应用需求
ChatGPT基于算力支撑实现交互革命有不少先进性
1 模型训练效率提高;2 训练模式更具通用性,经济效益增强;3 反馈准确性提升;4 可以拒绝用户的不适当请求;5 能够承认错误,挑战不正确的前提
基于RLHF的算法优化,助力GPT模型革新
通过奖励模型产生最优的输出结果后,将该结果对模型参数进行迭代与优化,到高质量的ChatGPT模型,构建的Codex模型上引入了推理能力
从AlphaGo到ChatGPT,AI技术发展叩响AGI之门
ChatGPT在文字创作与语言交互等方面的能力令人惊喜,一定程度上实现了人类同等能力,提升读写效率,实现AGI具有可能性,重塑AI发展前景 |
| 智能运输机器人 |
| AGV无人运输机器人-料箱版 |
| AGV无人运输机器人-标准版 |
| AGV无人运输机器人-料箱版(钣金材质) |
| AGV无人运输机器人-货架版(钣金材质) |
| AGV无人运输机器人-货架版(亮面不锈钢材质) |
| AGV无人运输机器人-开放版 |
| 行业动态 |
