
| 详细信息 |
Flickr8k-CN Flickr30k-CN 数据集 |
| 编辑: 来源:华泰证券 时间:2023/5/19 |
Flickr8k-CN & Flickr30k-CN 数据集:于 2017 年由浙江大学和人民大学联合发布。 Flickr8k-cn 是公共数据集,每个测试图像与 5 个中文句子相关联,这些句子是通过手动翻 译 Flickr8k 中对应的 5 个英文句子获得的。Flickr30k-cn 是 Flickr30k 的双语版本,通过其 训练/有效集的英译汉机器翻译和测试集的人工翻译获得。
|
| 【声明:转载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述,文章内容仅供参考,如有侵权,请联系删除。】 |
| 推荐信息 |
|
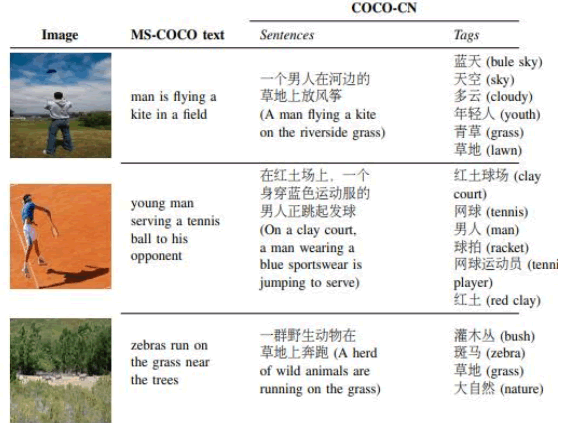
COCO-CN数据集-中国人民大学
COCO-CN数据集拥有20342张图片,27218 个中文句子和 70993 个标签,为跨语言图像标注,字幕和检索提供了一个统一平台
Zero数据集-大规模的中文跨模态基准
Zero是一种大规模的中文跨模态基准测试,其中包含目前最大的公共预训练数据集ZERO-Corpus和五个用于下游任务的人工注释微调数据集
Noah-Wukong数据集-华为诺亚方舟实验室
诺亚悟空数据集是一个大规模的多模态中文数据集,包含100万对图文对,数据集中的图像根据大小和宽高比进行过滤
MUGE数据集[清华大学和阿里巴巴]
MUGE数据集,于 2021 年由清华大学和阿里巴巴联合发布,包括图像描述,图像文本检 索和基于文本的图像生成 3 种多模态理解和生成任务
MATINF数据集-武汉大学和密歇根大学
MATINF数据集 是一个联合标注的大规模数据集,用于中文母婴护理领域的分类,问答和总结,数据集中的一个条目包括四个字段,问题,描述,类别和答案
ODSQA 数据集-台湾大学
ODSQA数据集由台湾大学发布。ODSQA 数据集是用于中文问答的口语数据 集。它包含来自 20 位不同演讲者的三千多个问题
Douban Conversation Corpus 数据集
豆瓣会话语料库包括一个训练数据集、一个开发集和一个基于检索的 聊天机器人的测试集,测试数据包含 1000 个对话上下文
E-KAR数据集-复旦大学
E-KAR数据集包含来自公务员考试的 1,655 个(中文)和 1,251 个(英文)问题,这 些问题需要深入的背景知识才能解决 |

| 智能运输机器人 |
| AGV无人运输机器人-料箱版 |
| AGV无人运输机器人-标准版 |
| AGV无人运输机器人-料箱版(钣金材质) |
| AGV无人运输机器人-货架版(钣金材质) |
| AGV无人运输机器人-货架版(亮面不锈钢材质) |
| AGV无人运输机器人-开放版 |
| 行业动态 |
