
| 详细信息 |
E-KAR数据集-复旦大学 |
| 编辑: 来源:华泰证券 时间:2023/5/19 |
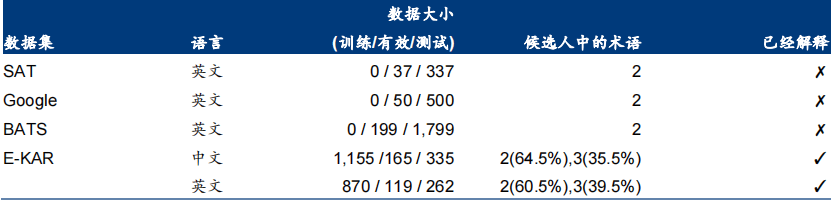
E-KAR 数据集:于 2022 年由复旦大学、字节跳动人工智能实验室和 BrainTechnologies,Inc. 联合发布。数据集包含来自公务员考试的 1,655 个(中文)和 1,251 个(英文)问题,这 些问题需要深入的背景知识才能解决。
|
| 【声明:转载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述,文章内容仅供参考,如有侵权,请联系删除。】 |
| 推荐信息 |
|
FCGEC数据集-浙江大学
FCGEC数据集用于检测,识别和纠正 语法错误,是一个人工标注的多参考语料库,由 41340 个句子组成,主要来自公立学校语 文考试中的选择题
DRCD数据集-台达
DRCD数据集中文机器阅读理解数据集,包含来自 2108 篇维基百科文章的 10014 个段落和由注释者生成的 33,941 个问答对
Ape210K数据集-猿辅导 AI Lab
Ape210K是一个新 的大规模和模板丰富的数学单词问题数据集,包含 210K 个中国小学水平的数学问题,包含黄金答案和得出答案所需的方程式
Math23K数据集-解决数学问题数据集
Math23K是为解决数学问题而创建的数据集,数据包含从在线教育网站上抓取的 6 万多个中文数学单词问题,都是小学 生真正的数学应用题
CAIL2018数据集 中国法律数据
CAIL2018是第一个用于判决预测的大规模中国法律数据集,收录 了中国最高人民法院公布 260 万件刑事案件,由适用的法律条款指控和刑期组成
中国开源大语言模型数据集 WuDaoCorpora数据集
WuDaoCorpora数据集采用 20 多种规则从 100TB 原始网页数据中清洗得出最终数据集,注重隐私数据信息的去除,支持多领域预训练模型的训练
中国开源大语言模型数据集 DuReader数据集
DuReader是一个大规模的开放域中文机器阅读理解数据集,问题和文档基于百度搜索和百度知道,答案是手动生成的,由200K问题,420K答案和1M文档组成
中国多模态大模型数据集构建
阿里M6大模型参数规模达到 1000 亿,构建了最大的中文多模态预训练数据集 M6-Corpus;百度ERNIE-ViLG大模型参数规模达到 100 亿 |
| 智能运输机器人 |
| AGV无人运输机器人-料箱版 |
| AGV无人运输机器人-标准版 |
| AGV无人运输机器人-料箱版(钣金材质) |
| AGV无人运输机器人-货架版(钣金材质) |
| AGV无人运输机器人-货架版(亮面不锈钢材质) |
| AGV无人运输机器人-开放版 |
| 行业动态 |
