
| 详细信息 |
机器人从大型语言模型和视觉-语言模型中学习各种操作 |
| 编辑: 来源:CAAI认知系统与信息处理专委会 时间:2023/7/14 |
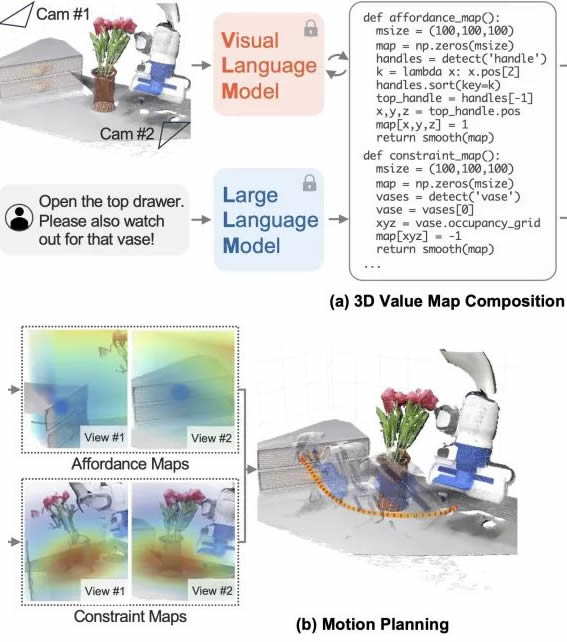
大型语言模型(LLM)被证明拥有丰富的可操作知识,可以以推理和计划的形式提取用于机器人操作。尽管取得了进展,但大多数仍然依靠预定义的运动基元来执行与环境的物理交互,这仍然是一个主要瓶颈。 在这项工作中,研究的目标是合成机器人轨迹,即密集的6-DoF末端执行器航点序列,用于给定开放指令集和开放对象集的各种操作任务。LLM擅长推断自由形式的语言教学的提供和约束来实现这一点。更重要的是,通过利用他们的代码编写能力,可以与视觉语言模型(VLM)交互,以组合3D价值图,将知识置于代理的观察空间中。然后将组合的值图用于基于模型的计划框架中,以零镜头合成闭环机器人轨迹,并具有对动态扰动的鲁棒性。
给定环境的RGB-D观察和语言指令,LLM生成与VLM交互的代码,以生成一系列基于机器人观察空间的3D提供图和约束图(统称为值图)(a)组合的值图用作运动规划器的目标函数,以合成机器人操作的轨迹(b)整个过程不涉及任何额外的训练。 展示了所提出的框架如何通过有效地学习涉及接触丰富交互场景的动态模型来在线测试。在模拟和真实机器人环境中对所提出的方法进行了大规模研究,展示了以自由形式的自然语言执行30多种日常操作任务的能力。 估计物理特性:给定两个未知质量的块,机器人的任务是使用可用的工具进行物理实验,以确定哪个块更重。 行为常识推理:在机器人设置桌子的任务中,用户可以指定行为偏好,例如“我是左撇子”,这需要机器人在任务的上下文中理解其含义。 细粒度语言校正:对于需要G精度的任务,例如“用盖子盖住茶壶”,用户可以向机器人发出准确的指令,例如“您离开了1cm”。 多步可视化程序:给定一个任务“将抽屉准确地打开一半”,由于对象模型不可用,信息不足,机器人可以根据视觉反馈提出多步骤操作策略,先在记录手柄位移的同时完全打开抽屉,然后将其关闭回中点以满足要求。
|
| 【声明:转载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述,文章内容仅供参考,如有侵权,请联系删除。】 |
| 推荐信息 |
|
机器人Glow与机器人Character.AI对比
机器人Glow应用场景是情感陪伴,奇幻联想;机器人Character应用场景是情感陪伴、奇幻联想、头脑风暴、制定计划等
机器人Charater虚构人物类型丰富 供更接近真人的沟通体验
机器人Charater共有68类虚构人物标签,满足多元用户的多样话题交谈需求;可在对话中生成与识别图片,图像生成能力有进一步优化空间
C端消费者娱乐的AI聊天机器人Charater.AI
AI聊天机器人Charater自行创建具有特定个性,人设和知识储备的聊天机器人,具备更丰富的虚构人物,可识别和生成图片,支持语音输入 ,支持群聊等特色
MiniMax与OpenAI具有相似的商业模式规划,均发掘C端和B端变现场景
推出了C端聊天机器人Glow暂未开放收费;MiniMax从2023年起会逐步开放API,让更多的个人用户和企业用户基于多种模态的大模型构建自己的应用
机器人Glow核心为三大模态的基础模型架构User-in-the-Loop
Glow基于“User-in-the-Loop”进行产品输出结果的人为优化,模型将由此强化对用户对话喜好的认知,从而优化产品体验
聊天机器人Glow与其他社交APP(微信 ChatGPT)对比
,Glow或在一定程度上更好地解决用户情感陪伴以及奇幻情景联想的需求,从而增强用户的使用粘性;满足用户对虚构人物虚构场景的幻想
聊天机器人Glow提供情感陪伴体验,辅助虚构情景联想
Glow内智能体暂时无法反馈图片内容,用户可以与智能体就任何话题内容进行聊天,可以根据特定的话题,选择关联的智能体进行聊天
AI情感陪伴聊天机器人Glow,有约500万用户
用户在应用中创建AI机器人智能体,智能体将基于用户描述的性格,人设,头像及选定的音色等,将具备特定名人的有关知识储备,与用户开展实时沟通,互动 |
| 智能运输机器人 |
| AGV无人运输机器人-料箱版 |
| AGV无人运输机器人-标准版 |
| AGV无人运输机器人-料箱版(钣金材质) |
| AGV无人运输机器人-货架版(钣金材质) |
| AGV无人运输机器人-货架版(亮面不锈钢材质) |
| AGV无人运输机器人-开放版 |
| 行业动态 |
